

La intel·ligència artificial fa molta por! D’aquí poc els ordinadors pensaran per si mateixos i ens aniquilaran a tots. La fi s’acosta! O, com a mínim això és el que ens diuen les pel·lícules. A part, últimament tothom en parla: que si és un dels camps més importants actualment, que si proporcionarà canvis brutals…
Tot plegat, envoltat de misticisme i fomentat per un màrqueting que no ajuda a veure què és real i què és fum: diuen que no sabem com funciona, que és un procés completament opac, que les intel·ligències artificials o IA resoldran qualsevol problema del món mundial i ja no ens caldrà pensar mai més…
Avui a Ciència Oberta intentem explicar en què consisteix la Intel·ligència Artificial i una de les seves formes més esteses: les xarxes neuronals.
Intel·ligència?
A què ens referim exactament quan parlem d’intel·ligència artificial? És una part de la informàtica que pretén desenvolupar un ordinador perquè pensi com un humà. Aquesta idea pot englobar moltes coses, però actualment quasi tota la IA que es duu a terme consisteix en aprenentatge automàtic (en anglès, machine learning).
Ja vam explicar què era l’aprenentatge en els éssers vius: modificar una conducta a través de l’experiència. En els ordinadors és exactament el mateix. En aquest cas, l’experiència ve a través de les dades que donem o que obté l’ordinador.
Així, per exemple, si volem predir quan plourà, a través d’una IA donarem moltes dades meteorològiques antigues a l’ordinador i esperarem que tregui conclusions sobre quines condicions específiques es donen just abans del diluvi. La gràcia és que la capacitat de l’ordinador pot detectar variacions molt petites que segurament no es poden veure amb models clàssics meteorològics a gran escala –“clàssics” fa referència al fet que no utilitzen aprenentatge automàtic.

Ens hem inventat la sopa d’all…
És exactament el mateix que aquella saviesa de poble, quan la gent gran sap si plourà o no depenent d’on provenen els núvols. A base d’anys de mullar-se han identificat un patró. Els meteoròlegs apliquen un model que entenen i fan prediccions: plou quan els núvols venen de tal muntanya perquè queden atrapats a la vall i, en canvi, amb els que venen de l’altre costat això no passa. Tanmateix, aquesta saviesa només es basa a buscar un patró sense preocupar-se massa de la justificació.
Anàlogament, l’ordinador es mira totes les dades que li donem i intenta buscar aquest mateix patró. Si el troba, però, no en sabem exactament la justificació. Igual que els vells del poble, doncs, però amb la diferència que l’ordinador pot discernir entre si els núvols venen d’un metre més a la dreta o més a l’esquerra i predir resultats diferents i molt més precisos.
Diferents tipus d’aprenentatge
L’aprenentatge automàtic tampoc és tan senzill. Primer de tot, cal fer el procés d’entrenament. Aquí podem distingir dos tipus d’aprenentatge:
- Aprenentatge supervisat: donem a l’ordinador unes dades d’entrada amb dades de sortida i aquest intenta aprendre a predir la sortida. Aprendre de la meteorologia seria un exemple d’aprenentatge supervisat.
- Aprenentatge no supervisat: donem a l’ordinador tot de dades i aquest intenta descobrir-ne patrons. Classificar dades en grups semblants és una de les aplicacions més típiques de l’aprenentatge no supervisat. Això ens pot servir, per exemple, per separar per afinitat política usuaris en una xarxa social.
La forma més habitual d’aprenentatge automàtic és el supervisat i és en el que ens centrarem en aquest reportatge.
Molt bé… però com es fa?
Ens cal algun algorisme, un mètode per fer que l’ordinador aprengui de les dades. En el cas de l’aprenentatge supervisat n’hi ha uns quants, però el més usat amb diferència són les xarxes neuronals.
Una xarxa neuronal no és més que una sèrie de capes de neurones connectades entre elles. Això no obstant, què és una neurona per un ordinador? Semblant a una neurona del cervell, una neurona artificial és una unitat de processament que rep una sèrie d’entrades de les neurones anteriors, realitza uns càlculs i en treu una sortida.
La idea d’una xarxa neuronal és donar les dades recollides a la primera capa de neurones; aquestes combinen les dades d’alguna forma i en treuen una sortida que és processada per la següent capa de neurones. Depenent de l’aplicació es posen més o menys capes de neurones i, al final, l’última capa treu el resultat que volem.
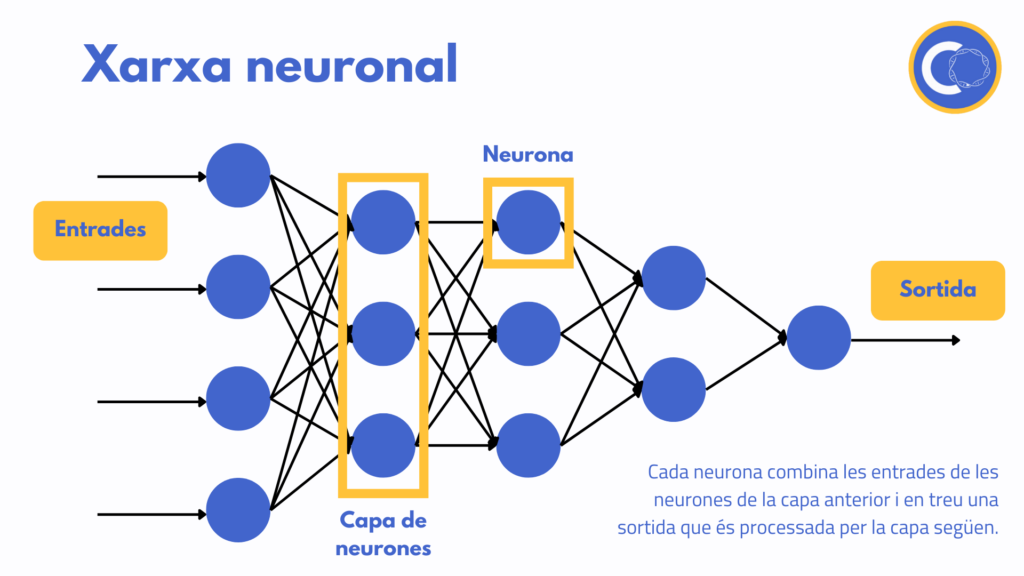
La forma de combinar les entrades a dins de cada neurona és molt senzilla. El que es fa és multiplicar-ne cada una per una constant que s’anomena pes i després sumar-les. Imaginem-ne un exemple molt senzill amb una única neurona: volem definir el preu d’un pis. El programa ens demana com a entrada els metres quadrats i l’estat del pis -mesurat d’alguna forma quantitativa.
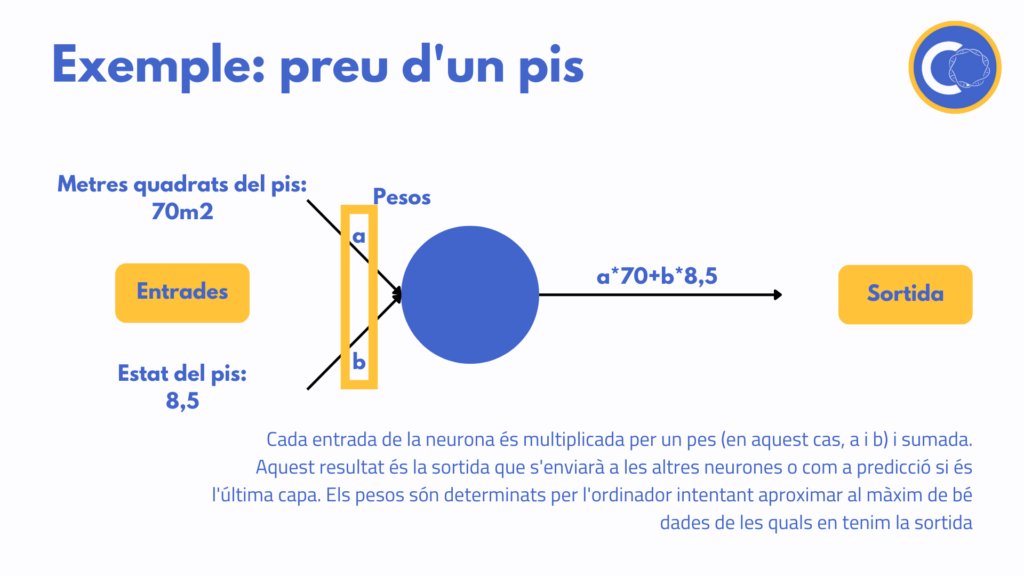
Podríem definir el preu del pis com la multiplicació dels metres quadrats per una constant -el preu per metre quadrat- i sumar-li o restar-li l’estat del pis també multiplicat per un pes. Això sembla aplicar una fórmula normal. La diferència és que nosaltres no posem els valors dels pesos -en aquest cas el preu per metre quadrat o el valor de l’estat de l’immoble- sinó que deixem que l’ordinador els extregui d’altres dades que tenim -per exemple de pisos de la mateixa zona que s’han venut recentment.
Com trobem els pesos?
Per trobar tots aquests pesos de les xarxes neuronals es recorre a un mètode que es diu retropropagació o backpropagation en anglès. Però, malgrat que sembli una cosa molt esotèrica, està basat en un mètode típic d’optimització anomenat descens de màxim gradient.
Primer de tot, el que fem és reservar una part de les dades de les quals disposem. Així, podrem mirar com de bé aproxima aquestes dades la xarxa que ja ha après. Seguint amb l’exemple de la pluja, si tenim dades dels últims 10 anys, entrenem la xarxa neuronal amb les dades de 2011 a 2020 i reservem les del 2021 per quantificar com de bé prediu els resultats la nostra IA.
Podem definir amb aquestes dades un rendiment: com millor aproximi el programa les dades que hem reservat, més rendiment tindrà. Llavors només cal anar variant els pesos fins a descobrir la combinació de més rendiment.
Variar-los a la babalà seria impossible computacionalment, sobretot amb xarxes amb moltes capes i, per tant, molts pesos, i per això es fa servir el backpropagation. Aquesta tècnica consisteix a agafar un estat inicial qualsevol dels pesos i mirar quina petita variació augmenta més el rendiment. Llavors continuar augmentant aquesta mateixa variació fins que el rendiment deixi de créixer i tornar a fer el mateix procediment.
Això ens porta molt ràpidament a un màxim de rendiment, però és un màxim local; podria ser que partint d’uns altres valors inicials arribéssim a un altre màxim millor. És per això que en aprenentatge automàtic és molt important com triem l’estat inicial de la xarxa.
Ja per acabar…
Com s’ha vist en els darrers anys, l’aprenentatge automàtic té moltes aplicacions en tots els camps, des de reconeixement d’imatges fins a detectar malalties molt abans que n’apareguin els símptomes, passant per predir com es pleguen les proteïnes.
Això no obstant, a part que se’n pot fer un ús poc ètic -com el de controlar i manipular la societat- aquesta tecnologia porta un problema profund adscrit: està condicionat a les dades que els donem per l’aprenentatge. Així, apareixen casos com el de la IA de Twitter, que va aprendre a ser racista, xenòfoba i sexista a causa de les converses que tenia amb membres d’aquesta xarxa.
Ens cal ser prudents i -com sempre- fer servir totes aquestes noves eines tan potents amb esperit crític i reflexió.
Per saber-ne més
Viquipèdia – Aprenentatge Profund
Viquipèdia – Algorisme del gradient descendent
Wikipedia – Unsupervised Learning
Imatges extretes de:
1. W.carter, CC0, via Wikimedia Commons
2 i 3 són de creació pròpia.
Imatge de Portada: Mike MacKenzie .






